

업로드를 했어야 했는데..
현강 끝나고 집에 와서 눕고나서 차마 일어날 수가 없었다..
바로 숙면
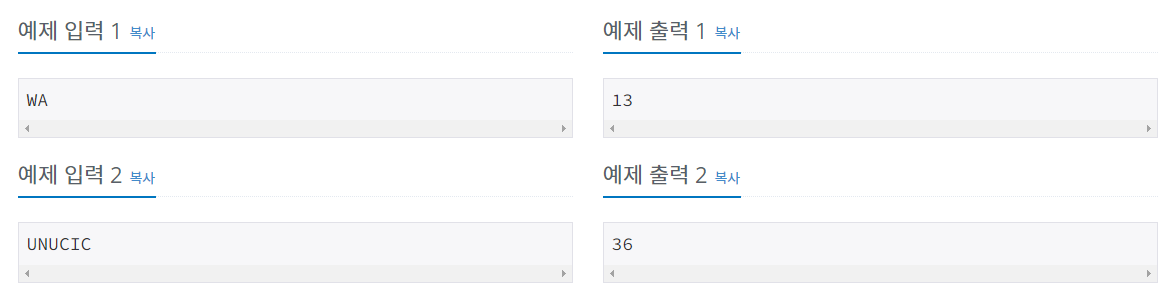
10809 - 알파벳 찾기
(https://www.acmicpc.net/problem/10809)
1. 문제
알파벳 소문자로만 이루어진 단어 S가 주어진다. 각각의 알파벳에 대해서,
단어에 포함되어 있는 경우에는 처음 등장하는 위치를,
포함되어 있지 않은 경우에는 -1을 출력하는 프로그램을 작성하시오.
2. 입력
첫째 줄에 단어 S가 주어진다. 단어의 길이는 100을 넘지 않으며, 알파벳 소문자로만 이루어져 있다.
3. 출력
각각의 알파벳에 대해서, a가 처음 등장하는 위치, b가 처음 등장하는 위치, ... z가 처음 등장하는 위치를
공백으로 구분해서 출력한다.
만약, 어떤 알파벳이 단어에 포함되어 있지 않다면 -1을 출력한다.
단어의 첫 번째 글자는 0번째 위치이고, 두 번째 글자는 1번째 위치이다.
-틀린 코드-
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from string import ascii_lowercase # 소문자 알파벳 불러오기
S = input() #문자열 입력 받기
dict_az = {} #a~z까지 밸류값 가지는 딕셔너리
lst_az = [] #a~z까지 순서대로 있는 리스트
lst_chr = [] #S의 글자별 리스트
count = -1 #기본값으로 그 알파벳이 없는 걸 상정(-1로 출력해야함)
for i in ascii_lowercase:
dict_az[i] = -1 #{'a':-1, 'b':-1 .....}
lst_az.append(i) #['a','b','c'....]
for i in range(len(S)):
lst_chr.append(S[i]) #lst_chr = ['b','a','e','k','j','o','o','n']
for i in lst_chr:
if i in dict_az: #lst_chr의 글자들이 dict_az에 key로 있다면
count += 1 #count에 1을 더한다
dict_az[f'{i}'] = count #그 count 값을 해당하는 알파벳(key)의 value값으로 지정한다.
|
cs |
이렇게 되면 겹치는 코드(예시 'baekjoon' 에서는 'o')가 나왔을 때 가장 마지막 순서로 카운트 된다.
예제 출력에서 'o'는 5 / 내 출력에서는 6
그래서 중복되는 걸 어떻게 해줘야할까 고민을 하는데 잘 안 떠올라서 검색해봤다.
-맞힌 코드-
|
1
2
3
4
5
|
S = input()
alph = list(range(97,123)) #ascii 코드를 이용한다.
for x in alph:
print(S.find(chr(x)), end=' ') #chr()을 통해 숫자를 알파벳으로 변환한다. find함수는 없으면 -1, 있으면 그 인덱스를 반환한다.
|
cs |
굴복했다. 이걸 몰랐네~
2675 - 문자열 반복
(https://www.acmicpc.net/problem/2675)
4. 문제
문자열 S를 입력받은 후에, 각 문자를 R번 반복해 새 문자열 P를 만든 후 출력하는 프로그램을 작성하시오.
즉, 첫 번째 문자를 R번 반복하고, 두 번째 문자를 R번 반복하는 식으로 P를 만들면 된다.
S에는 QR Code "alphanumeric" 문자만 들어있다.
QR Code "alphanumeric" 문자는 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ\$%*+-./: 이다.
5. 입력
첫째 줄에 테스트 케이스의 개수 T(1 ≤ T ≤ 1,000)가 주어진다.
각 테스트 케이스는 반복 횟수 R(1 ≤ R ≤ 8), 문자열 S가 공백으로 구분되어 주어진다.
S의 길이는 적어도 1이며, 20글자를 넘지 않는다.
6. 출력
각 테스트 케이스에 대해 P를 출력한다.

-맞힌 코드-
|
1
2
3
4
5
6
7
8
9
10
|
T = int(input()) #테스트 케이스 개수를 받는다.
for i in range(T): #케이스 개수만큼 반복한다.
R, S = input().split() #R과 S를 받는다.
R = int(R) #R을 정수화한다.
for i in range(len(S)): #S의 길이만큼
print(S[i] * R, end='') #각 글자 * R만큼 붙여서 프린트한다.
print('') #위 for문을 돌렸다면 개행해준다.
|
cs |
1157 - 단어 공부
(https://www.acmicpc.net/problem/1157)
7. 문제
알파벳 대소문자로 된 단어가 주어지면,
이 단어에서 가장 많이 사용된 알파벳이 무엇인지 알아내는 프로그램을 작성하시오.
단, 대문자와 소문자를 구분하지 않는다.
8. 입력
첫째 줄에 알파벳 대소문자로 이루어진 단어가 주어진다. 주어지는 단어의 길이는 1,000,000을 넘지 않는다.
9. 출력
첫째 줄에 이 단어에서 가장 많이 사용된 알파벳을 대문자로 출력한다.
단, 가장 많이 사용된 알파벳이 여러 개 존재하는 경우에는 ?를 출력한다.

-맞힌 코드-
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#아스키(대문자)를 받아온다.
from string import ascii_uppercase
#word를 upper로 input받는다.
word = (input()).upper()
lst1 = []
lst2 = []
lst_alph = list(ascii_uppercase) #['A', 'B', ... , 'Z']
#word의 한글자씩 lst1에 할당한다.
for i in word:
lst1.append(i)
#dict를 이용해서 알파벳 : 갯수 로 딕셔너리화 한다.
dic1 = {}
for x in lst_alph:
dic1[x] = lst1.count(f'{x}')
#dic1에서 가장 큰 밸류값 v를 밸류로 갖는 k의 리스트를 lst2로 설정한다.
#lst2에 리스트를 할당할 건데, 그 리스트가 뭐냐면 #dic1의 가장 큰 value인 v를 가지는 key값 k를 갖는 리스트다. #검색했다. lst2 = [k for k,v in dic1.items() if max(dic1.values()) == v]
#그 값이 한 개라면 그 값을 출력하고, 그렇지 않다면 ?를 출력한다.
if len(lst2) == 1:
print(lst2[0])
else:
print('?')
|
cs |
한개의 최고값을 갖는 key 하나를 찾는 건 성공했는데,
동일하게 최고값을 갖는 두 key값을 찾는 방법을 몰라서 검색해서 알아냈다.
쉽지 않네..
1152 - 단어의 개수
10. 문제
영어 대소문자와 공백으로 이루어진 문자열이 주어진다. 이 문자열에는 몇 개의 단어가 있을까?
이를 구하는 프로그램을 작성하시오. 단, 한 단어가 여러 번 등장하면 등장한 횟수만큼 모두 세어야 한다.
11. 입력
첫 줄에 영어 대소문자와 공백으로 이루어진 문자열이 주어진다.
문자열의 길이는 1,000,000을 넘지 않는다.
단어는 공백 한 개로 구분되며, 공백이 연속해서 나오는 경우는 없다.
또한 문자열은 공백으로 시작하거나 끝날 수 있다.
12. 출력
첫째 줄에 단어의 개수를 출력한다.

-틀렸던 코드들-
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#시간초과 났던 코드
string = input()
noblank_string = string.rstrip().lstrip()
lst = []
for i in range(len(noblank_string.split(' '))):
lst.append(noblank_string.split(' ')[i])
print(len(lst))
#틀렸던 코드
string = input()
noblank_string = string.strip()
print(len(noblank_string.split(' ')))
|
cs |
#1 시간복잡도를 생각했어야 했다.
최대한 효율적인 연산을 해야하는 이유.
#2 단순히 공백을 입력했을 때도 카운트가 되어버린다.
-맞힌 코드-
2908 - 상수
(https://www.acmicpc.net/problem/2908)
13. 문제
상근이의 동생 상수는 수학을 정말 못한다. 상수는 숫자를 읽는데 문제가 있다.
이렇게 수학을 못하는 상수를 위해서 상근이는 수의 크기를 비교하는 문제를 내주었다.
상근이는 세 자리 수 두 개를 칠판에 써주었다. 그 다음에 크기가 큰 수를 말해보라고 했다.
상수는 수를 다른 사람과 다르게 거꾸로 읽는다.
예를 들어, 734와 893을 칠판에 적었다면, 상수는 이 수를 437과 398로 읽는다.
따라서, 상수는 두 수중 큰 수인 437을 큰 수라고 말할 것이다.
두 수가 주어졌을 때, 상수의 대답을 출력하는 프로그램을 작성하시오.
14. 입력
첫째 줄에 상근이가 칠판에 적은 두 수 A와 B가 주어진다. 두 수는 같지 않은 세 자리 수이며, 0이 포함되어 있지 않다.
15. 출력
첫째 줄에 상수의 대답을 출력한다.

-맞힌 코드-
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#a, b를 문자열로 받아준다.
a, b = input().split()
#둘 다 거꾸로 돌린다
a = a[::-1]
b = b[::-1]
#크면 출력한다.
if int(a) > int(b):
print(a)
else:
print(b)
|
cs |
근데 거꾸로 읽고 대소비교해서 대답할 정도면 똑똑한거 아니야?
5622 - 다이얼
(https://www.acmicpc.net/problem/5622)
16. 문제
상근이의 할머니는 아래 그림과 같이 오래된 다이얼 전화기를 사용한다.

전화를 걸고 싶은 번호가 있다면, 숫자를 하나를 누른 다음에 금속 핀이 있는 곳 까지 시계방향으로 돌려야 한다.
숫자를 하나 누르면 다이얼이 처음 위치로 돌아가고, 다음 숫자를 누르려면 다이얼을 처음 위치에서 다시 돌려야 한다.
숫자 1을 걸려면 총 2초가 필요하다. 1보다 큰 수를 거는데 걸리는 시간은 이보다 더 걸리며,
한 칸 옆에 있는 숫자를 걸기 위해선 1초씩 더 걸린다.
상근이의 할머니는 전화 번호를 각 숫자에 해당하는 문자로 외운다.
즉, 어떤 단어를 걸 때, 각 알파벳에 해당하는 숫자를 걸면 된다.
예를 들어, UNUCIC는 868242와 같다.
할머니가 외운 단어가 주어졌을 때, 이 전화를 걸기 위해서 필요한 최소 시간을 구하는 프로그램을 작성하시오.
17. 입력
첫째 줄에 알파벳 대문자로 이루어진 단어가 주어진다. 단어의 길이는 2보다 크거나 같고, 15보다 작거나 같다.
18. 출력
첫째 줄에 다이얼을 걸기 위해서 필요한 최소 시간을 출력한다.
-맞힌 코드-
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
#대문자 불러오기
from string import ascii_uppercase
#변수 세팅
string = input()
count = 0
lst = list(ascii_uppercase)
answer_lst = []
dic = {}
#숫자 할당(시행마다 1초 더 길리기 때문에 미리 1초 더함)
for i in lst[0:3]: #ABC
dic[i] = 3
for i in lst[3:6]: #DEF
dic[i] = 4
for i in lst[6:9]: #GHI
dic[i] = 5
for i in lst[9:12]: #JKL
dic[i] = 6
for i in lst[12:15]: #MNO
dic[i] = 7
for i in lst[15:19]: #PQRS
dic[i] = 8
for i in lst[19:22]: #TUV
dic[i] = 9
for i in lst[22:26]: #WXYZ
dic[i] = 10
#받은 문자를 딕셔너리를 통해 value로 변환, 리스트에 할당
for i in range(len(string)):
answer_lst.append(dic[string[i]])
#그 리스트의 합을 출력
print(sum(answer_lst))
|
cs |
하면서 이게 맞나.. 싶긴 했는데 일단 했다.
상근이 할머니가 똑똑하시네
프로젝트가 분명 네 개였는데
온데간데없이 하나로 줄어들 예정이다.
직접 해보거나 해야 겠다..

6번 테마의 8번째까지 총 52개 풀었어.
앞으로 333개의 문제가 남았어. (13.5%)
'PS > BOJ' 카테고리의 다른 글
| (백준, 파이썬) 그룹 단어 체커 (0) | 2022.06.03 |
|---|---|
| (백준, 파이썬) 확실하냐고 (3) | 2022.06.01 |
| (백준, 파이썬, 나중에) 한 수 배웠다 (2) | 2022.05.30 |
| (백준, 파이썬) 다이나믹 뙤약볕 (0) | 2022.05.29 |
| (백준, 파이썬) 내가 이겼다 + 단계 별 10% 달성 (3) | 2022.05.28 |