
1. 해시(Hash)는 뭘까?
해시를 이해하기 위해서는 우선 해시 함수를 먼저 알아야 한다. 해시함수의 의미는 다음 정도로 생각할 수 있다.
"임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수" (출처 : 위키)
"데이터를 저장하고 찾는데 사용되는 자료 구조의 한 종류. 찾고자 하는 문자열을 함수로 처리해 얻은 값으로 데이터의 위치를 찾는 방법을 말한다" (출처 : 블로그)
함수를 통해 기존의 데이터를 처리한 그 값이 해시가 되는 것이고, 그 값을 이용해서 고유한 인덱스를 갖게끔 해서 이용하는 것이다.
일종의 암호화를 통해서 그 값을 특정하고, 분류할 수 있게끔 만드는 것이라고 생각이 든다.
2. 해시는 왜 쓰는 것일까?
공통된 것과 그렇지 않은 것 여러 정보를 가진 입력들이 각자 가지는 고유한 값들을 구분하고, 식별하기 위해서가 아닐까 싶다.
민감한 정보들을 조작할 때에도, 단순히 해시값을 역추적해서 알아내기는 어렵기 때문에 사용된다고 한다.
특히, 데이터의 개수와 크게 상관 없이 그 데이터가 갖고 있는 고유한 값을 이용해 탐색해내므로, 효율성이 높다.
3. 파이썬에서 해시는 어떻게 쓰는 걸까?
내장함수에 이미 해시 함수('hash()')가 존재한다.
주로 어떠한 이름(문자열)과 그 이름이 갖는 특정한 값(주소, 전화번호 등)들을 담기 때문에, 딕셔너리를 주로 이용한다.
hash("ssuamje")의 리턴 값은 해시 함수의 기묘한 과정을 통해서, 세상에 둘도 없을 것만 같은 값을 리턴한다.

이제 해시를 이용해서 문제를 풀어보자.
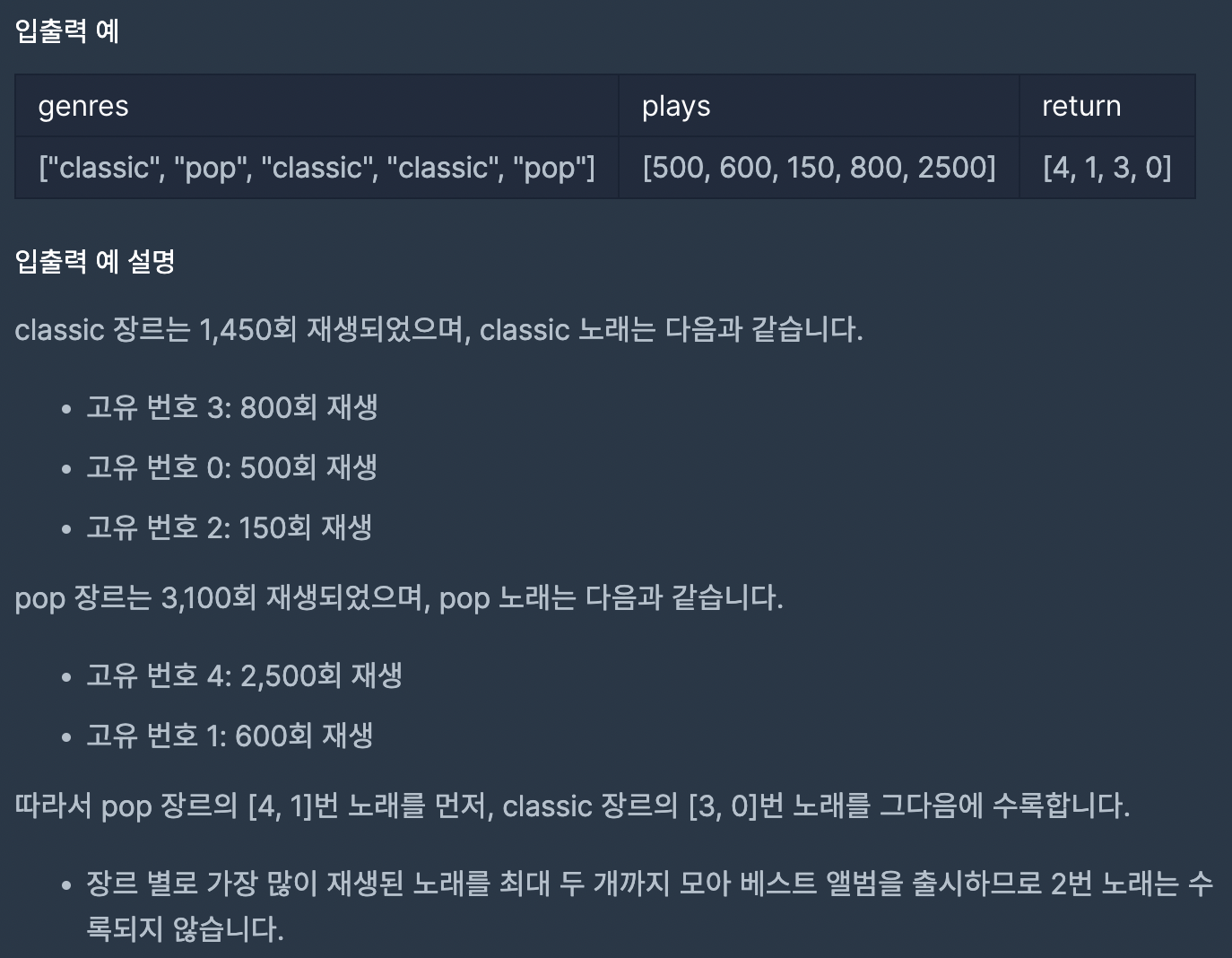

조건을 정리하면 다음과 같다.
- 고유번호를 인덱스로, 장르를 값으로 갖는 배열 genres와 그 인덱스별로 스트리밍 수가 적힌 plays가 인자로 주어진다.
- 각 곡의 재생횟수를 다 합쳐서, 가장 많은 장르부터 베스트 앨범에 수록한다.
- 각 장르별 두곡이고, 재생횟수가 높은 곡부터 수록한다.
- 같은 재생횟수를 가진다면, 고유 번호가 낮은(인덱스가 앞 쪽인) 노래를 수록한다 / 각 장르의 재생횟수는 다르지만 곡은 같을 수 있다.
#많이 재생된 장르 먼저
#장르 중에서 많이 재생된 노래 두개 먼저
#같은 횟수라면 고유번호가 낮은 노래 먼저
def solution(genres, plays):
sum_genre_streams = {} #장르별 스트리밍 총합
index_streams = {} #장르의 인덱스 별 스트리밍 수
best_album = [] #최종 반환할 베스트 앨범
for i in range(len(genres)): #모든 장르를 돌면서 == 장르의 개수만큼
if hash(genres[i]) not in sum_genre_streams: #각 장르의 해쉬값이 안 들어가있으면
sum_genre_streams[hash(genres[i])] = plays[i] #장르 : 스트리밍합 딕셔너리에 만들어준다
index_streams[i] = plays[i] #고유번호 : 스트리밍 딕셔너리에 삽입한다
else:
sum_genre_streams[hash(genres[i])] += plays[i] #장르 : 스트리밍 딕셔너리에 스트리밍 값을 더해준다
index_streams[i] = plays[i]
index_streams = sorted(index_streams.items(), key = lambda x : x[1], reverse = True) #고유번호 : 스트리밍 딕셔너리를 스트리밍 수를 기준으로 내림차순 정렬한다.
sum_genre_streams = sorted(sum_genre_streams.items(), key = lambda x : x[1], reverse = True) #장르 : 스트리밍합 딕셔너리를 ...
stream_th = 0 #내림차순으로 되어있는 장르의 인덱스
while stream_th < len(sum_genre_streams): #모든 장르를 도는 동안
count_inserted = 0 #베스트 앨범에 넣은 횟수를 초기화한다.
for index_stream in index_streams: #스트리밍이 높은 곡 순서대로
if count_inserted == 2: #두곡이 들어갔다면 종료한다.
break
index = index_stream[0] #인덱스와
stream = index_stream[1] #스트림 수를 구분해준다
if hash(genres[index]) == sum_genre_streams[stream_th][0]: #만약 현재 곡이 찾고 있는 장르라면
best_album.append(index) #베스트 앨범에 그 곡을 넣고
count_inserted += 1 #넣은 횟수를 증가시킨다.
else:
continue #찾고 있는 장르에 해당하지 않는다면 그 곡은 넘긴다.
stream_th += 1 #찾고 있는 장르의 두 곡을 넣었다면 다음 장르로 넘긴다.
return best_album풀이 논리를 정리하면 다음과 같다.
1. 각 장르별 총 스트리밍 수(sum_genre_streams)를 구하고, 가장 많이 재생된 장르부터 내림차순으로 정렬한다.
2. 각 곡의 고유번호 : 스트리밍 수가 적힌 딕셔너리(index_streams)를 만들고, 스트리밍 수를 기준으로 내림차순으로 정렬한다.
3. index_streams가 내림차순이기 때문에, 가장 많이 재생된 장르를 기준으로 두고 차례대로 넘어가는 상태에서(while 분기) 각 곡의 고유번호에 해당하는 장르를 확인(hash(genres[index]로 장르 해시값 확인)해서 현재 분기에 해당하는 장르라면, best_album에 넣고, 넣은 횟수(count_inserted)를 증가시킨다.
4. 이 때, count_inserted는 매 장르별로 초기화되어야 한다.
장르 / 고유번호 / 스트리밍 수 라는 세 가지 정보를 이용해서 순서를 구분하고 정리해야했다.
장르의 해시값을 이용해서 기존의 배열을 조작하는 것이 아닌 새로운 딕셔너리를 만들어서 탐색해내는 것이 포인트가 아니었나 싶다.
이외에도 다른 해시 문제들을 풀면서 해시의 사용방법과 사용해야하는 때에 대한 감각을 익힌 것 같다.
남의 풀이 안 보고 혼자서 풀었을 때 오랜만에 짜릿했다.
'PS > 프로그래머스' 카테고리의 다른 글
| (프로그래머스, 파이썬) 힙 - [더 맵게, 디스크 컨트롤러, 이중우선순위큐] (0) | 2022.10.26 |
|---|---|
| (프로그래머스, 파이썬) 정렬 : [K번째 수, H-index, 가장 큰 수] (0) | 2022.06.22 |