
1. 노션으로 보기
2. 개요
이전 느린 응답 26배 빠르게 개선해보기를 겪으면서, 복잡한 쿼리들을 메서드 체이닝을 이용해서 가져올 수 있었다면(QueryDSL을 썼다면) 이런 느린 쿼리 말고도 연관관계가 깊은 복잡한 쿼리들도 단번에 가져올 수 있지 않을까하는 생각이 들었다.
이번 글에서는 ORM과 JPA에 대해서 간단히 알아보고, QueryDSL의 간단한 적용과 예시를 구현해보고자 한다.
이를 통해서 추후에 직접 서비스에 적용해서 위에서 일어났던 휴먼 에러와 몰라서 생기는 불필요한 호출들을 줄일 수 있으면 좋겠다!
3. ORM부터 Spring Data JPA까지
우선 QueryDSL로 넘어가기 전에, 간단하게 ORM과 Spring Data JPA에 대해서 짚고 가보자.
3.1. ORM(Object-Relational-Mapping)

**객체 관계 매핑(ORM)**은 데이터베이스와 객체 지향 프로그래밍 언어 간의 호환되지 않는 데이터를 변환하는 프로그래밍 기법이다. 객체 지향 언어에서 사용할 수 있는 "가상" 객체 데이터베이스를 구축하는 방법이다.
간단하게 말하면 ‘백엔드 서버(WAS, Web Application Server)와 DB 서버간의 데이터 형변환’이라고 생각할 수 있겠다. 다음 코드를 생각해보자.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Member {
private Long id;
private String name;
private Integer age;
public static Member of(String name, Integer age) {
Member member = new Member();
member.name = name;
member.age = age;
return member;
}
}
위 Member는 ‘WAS의 객체’이다.
DB에 member라는 테이블이 있고, 그곳에 id, name, age라는 column이 있다고 하자. 물론 우리 눈에는 같은 데이터처럼 보일 수는 있다. 하지만..
DB와 WAS는 서로 다른 방식의 데이터 양식을 가진다.
이 둘을 DB와 WAS가 한 몸처럼 유연하게 읽기, 쓰기를 하기 위해 ORM을 사용하는 것이다.
ORM은 단순히 한 언어나 프레임워크에만 국한되는 개념은 아니다. Object와 연관해서 DB와 상호 Mapping하면 그것이 ORM인 것이다.
3.2. JDBC와 Hibernate
JDBC(Java Database Connectivity)는 자바에서 데이터베이스에 접속할 수 있도록 하는 자바 API이다. JDBC는 데이터베이스에서 자료를 쿼리하거나 업데이트하는 방법을 제공한다. → DB와 가장 맞닿아있는 저수준의 영역이며, 각 DB에 대해 알맞게 구현하도록 Interface를 명세한다.
Hibernate는 ORM을 제공하는, JDBC, 그리고 JPA(인터페이스)를 준수하는 프레임워크다.
… 초략 Hibernate는 Java 환경을 위한 객체/관계형 매핑(ORM) 솔루션입니다. … 중략 Hibernate는 Java 클래스에서 데이터베이스 테이블로, Java 데이터 유형에서 SQL 데이터 유형으로 매핑하는 작업을 처리합니다. 또한 데이터 쿼리 및 검색 기능도 제공합니다. 이를 통해 SQL 및 JDBC에서 수동으로 데이터를 처리할 때 소요되는 개발 시간을 크게 줄일 수 있습니다. Hibernate의 설계 목표는 SQL과 JDBC를 사용하여 수작업으로 데이터를 처리할 필요가 없도록 함으로써 개발자가 일반적인 데이터 지속성 관련 프로그래밍 작업의 95%에서 벗어날 수 있도록 하는 것입니다. 그러나 다른 많은 지속성 솔루션과 달리 Hibernate는 SQL의 강력한 기능을 숨기지 않으며 관계형 기술 및 지식에 대한 투자가 항상 유효하도록 보장합니다. - Hibernate 공식 문서
3.3. Spring Data JPA
JPA는 Java Persistence API를 의미한다.
DB는 ‘영속적인(Persistence)’ 데이터를 저장하고, 꺼내주는 것이고, 이를 이용하게끔 해주는 Java의 API라는 얘기다.
엄밀히 말하면 Spring Data JPA는 JPA를 쓰기 쉽게 해주는 모듈이다. 위에 썼듯, Hibernate가 JPA 인터페이스를 준수하는 구현이고, Spring Data JPA가 유용하게 사용할 수 있게끔 하는 모듈이자 프레임워크인 것이다.
Spring Data JPA는 실제로 필요한 만큼만 작성하도록 함으로써 데이터 액세스 계층(영속성 계층)의 구현을 크게 개선하는 것을 목표로 합니다. 개발자는 사용자 정의 파인더 메서드를 포함한 리포지토리 인터페이스를 작성하면 Spring이 자동으로 구현을 제공합니다. - Spring 공식 문서
JPA는 Java 개발자에게 Java 애플리케이션에서 관계형 데이터를 관리할 수 있는 객체/관계형 매핑 기능을 제공합니다. Java Persistence는 세 가지 영역으로 구성됩니다: (예시는 Spring Data JPA를 기준으로 작성했다)
- Java Persistence API → 추상화되어 편히 사용할 수 있는 API들을 의미한다. ex) DomainRepository.findById(domainId)
- 쿼리 언어(Query Language) → 쿼리를 사용할 수 있게끔 해주는 것을 의미한다. ex) @Query(”SELECT c FROM Cabinet c”) 여기서 특징은 Cabinet 클래스를 다루듯이 쓸 수 있다는 점!
- 객체/관계형 매핑 메타데이터(Meta Data) → 클래스와 데이터베이스 테이블 간의 매핑을 지정하는 데이터들을 의미한다. ex) @Entity, @Table, @Id 등등
- 오라클 튜토리얼
즉, JPA를 통해서 우리는 WAS에서 마치 DB를 이리저리 만지는 것(읽기/쓰기)과 동일한 행위를 수행할 수 있다!
위 Member 클래스를 JPA를 이용해 메타데이터들을 이용해서 ORM(JPA) 가능하게 변경시켜보자.
@Entity // 엔티티임을 나타내는 메타데이터
@Table(name = "MEMBER") // DB의 어느 테이블에 속하는지 알려주는 메타데이터
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Member {
@Id // Primary Key임을 알려주는 메타데이터
@GeneratedValue(strategy = GenerationType.AUTO) // 생성 전략을 알려주는 메타데이터
@Column(name = "MEMBER_ID") // 컬럼 명을 알려주는 메타데이터
private Long id;
@Column(name = "NAME")
private String name;
@Column(name = "AGE")
private Integer age;
public static Member of(String name, Integer age) {
Member member = new Member();
member.name = name;
member.age = age;
return member;
}
}
위와 같이 설정하면 우리는 객체를 DB의 데이터에 연동하여 쓰듯이 조작할 수 있게된다!
이제 JpaRepository를 인터페이스로(구현체 없어도 됨!) 작성하게 되면..
@Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("SELECT m " +
"FROM Member m " +
"WHERE m.name = '세계분의 비빔박자 유비빔'") // Query Language의 사용 - JPQL
Member findYouBibim();
}
/*--------------------------------------------------------------------*/
@Service
@RequiredArgsConstructor
public class MemberService {
private final MemberRepository memberRepository;
public void test() {
// 구현하지 않았음에도 save 메서드를 사용할 수 있다.
memberRepository.save(Member.of("세계분의 비빔박자 유비빔", 51));
// 미리 작성한 Query를 이용해 별도의 Query 메서드를 구현할 수 있다.
memberRepository.findYouBibim();
}
}
마법과 같은 일이 일어난다!
3.4. 중간 정리
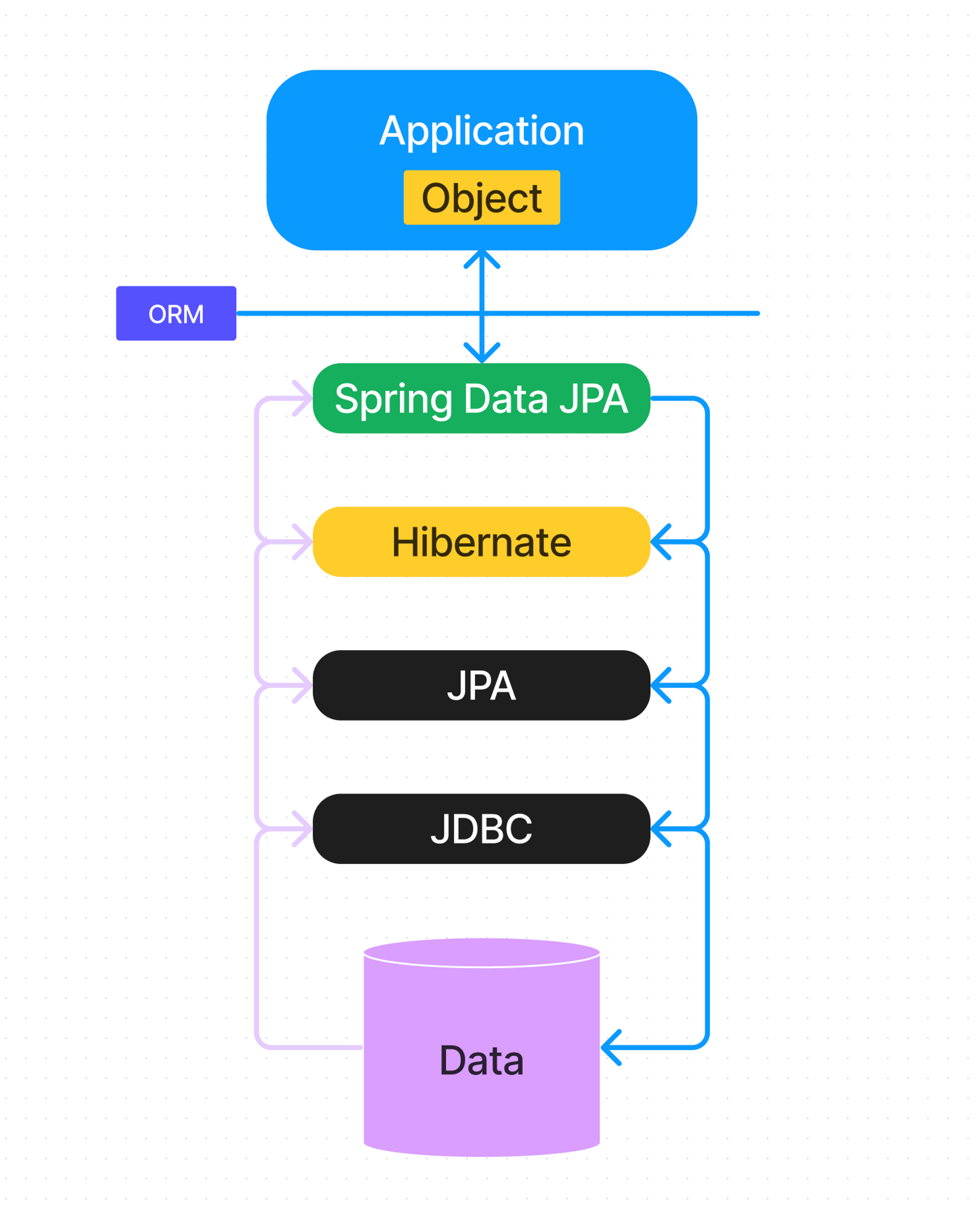
Java와 DB를 연결해주는 JDBC, 그리고 그를 기반으로 JPA를 준수하면서 ORM을 수행하는 Hibernate, 그리고 이를 사용하기 쉽게 추상화한 Spring Data JPA의 구조라고 생각해볼 수 있다.
이 정도만 되어도 JPA를 통해 우리가 하고 싶은 일들을 왕창 할 수 있지만, 더 고도화된 방법인 QueryDSL로 넘어가보자.
4. 그리고 QueryDSL
Querydsl은 HQL(Hibernate Query Language) 쿼리를 Type-Safe하게 유지보수해야 할 필요로 탄생했습니다. HQL 쿼리를 점진적(Incremental)으로 구성하려면 문자열 연결이 필요하며 그 결과 코드를 읽기 어렵습니다. 일반 문자열을 통한 도메인 타입 및 프로퍼티에 대한 안전하지 않은 참조는 문자열 기반 HQL 구성의 또 다른 문제였습니다.
Type-Safe하게 도메인 모델이 변경되면(QueryDSL을 쓰면) 소프트웨어 개발에서 안전성이 크게 향상됩니다. 도메인 변경 사항이 (쿼리를 수정하지 않더라도) 쿼리에 직접 반영되고, 쿼리 구성에서 자동 완성 기능이 쿼리 구성을 더 빠르고 안전하게 만들어 줍니다.
… 생략
- QueryDSL 공식문서
Querydsl은 타입 세이프한 SQL 쿼리형태를 자바 코드로 작성할 수 있게 해주는 프레임워크다.
주로 하이버네이트, JPA 같은 ORM 프레임워크와 함께 사용된다.
QueryDSL의 경우 Spring Data JPA의 리포지터리를 그대로 사용하지 않고, 커스텀하여 사용한다. Query용 별도 구현 클래스를 이용하여 구현하기 때문이다. → 이 덕에 기존과는 다르게 쿼리를 작성하면서도 Type-Safe하게 쓸 수 있는 것이고, 컴파일 타임에 오류를 잡아낼 수 있다.
4.1. 왜 QueryDSL을 쓰는가
QueryDSL을 왜 쓸까? 장단점에 대해서 알아보자.
- 장점
- QueryDSL은 컴파일 시점에 쿼리의 타입 체크를 가능하게 한다. 이는 런타임에 발생할 수 있는 이슈를 미리 방지하고 쿼리 오류를 줄인다.
- Querydsl은 문자열 기반의 JPQL/HQL 대신 자바 코드를 통해 쿼리를 작성하기 때문에 코드의 가독성이 좋다.
- Querydsl은 조건절을 메서드로 분리하여 쿼리 로직의 재사용이 가능하다.
- ⭐️⭐️⭐️동적 쿼리를 편하게 작성할 수 있다.
- 단점
- 여느 프레임워크가 그렇듯, QueryDSL의 추가적인 API를 배우고 해당 API를 사용하는 방법을 이해해야 한다.
- Querydsl은 자체 코드 생성을 통해 Q 클래스를 생성하는데, 이 과정은 초기 설정과 유지 보수가 필요할 수 있다.
- 정적 쿼리(Static Query)와 동적 쿼리(Dynamic Query)
- 정적 쿼리는 프로그램 실행 전에 모든 SQL 문들이 이미 정의되어 있고 런타임에 SQL을 변경할 수 없는 쿼리를 말한다.
- 동적 쿼리는 프로그램 런타임에 SQL 구문이 변경될 수 있는 쿼리다. 이는 보통 사용자의 입력을 기반으로 SQL 구문을 만들거나 조건에 따라 구문을 변경하는 등의 로직을 필요로 한다.
…
JPA의 아버지 김영한님의 코멘트
…
Spring Data JPA를 사용하던 복잡한 쿼리
@EntityGraph(attributePaths = {"cabinetPlace"})
@Query("SELECT DISTINCT c, lh, u " +
"FROM Cabinet c " +
"JOIN c.lentHistories lh ON lh.cabinetId = c.cabinetId " +
"JOIN lh.user u ON lh.userId = u.userId " +
"WHERE c.cabinetPlace.location.building = :building AND c.cabinetPlace.location.floor = :floor " +
"AND lh.endedAt IS NULL")
List<Object[]> findCabinetActiveLentHistoryUserListByBuildingAndFloor(
@Param("building") String building, @Param("floor") Integer floor);
위 쿼리를 QueryDSL로 변경한 모습
public List<Object[]> findCabinetActiveLentHistoryUserListByBuildingAndFloor(String building, Integer floor) {
return queryFactory
.select(cabinet, lentHistory, user)
.from(cabinet)
.innerJoin(cabinet.lentHistories, lentHistory)
.on(cabinet.cabinetId.eq(lentHistory.cabinetId))
.innerJoin(lentHistory.user, user)
.on(lentHistory.userId.eq(user.userId))
.where(cabinet.cabinetPlace.location.building.eq(building)
.and(cabinet.cabinetPlace.location.floor.eq(floor))
.and(lentHistory.endedAt.isNull()))
.distinct()
.fetch();
함수형으로 가시적으로 작성할 수 있음을 알 수 있다!
5. 정리

QueryDSL의 직접적인 사용 이전에 어떠한 구조를 갖는지 알아보았다.
이제 구현을 하러가보자. → 예제로 QueryDSL 사용해보기
5.1. 참고자료
A Guide to Querydsl with JPA | Baeldung
Introduction to the Java Persistence API - The Java EE 5 Tutorial
'JAVA' 카테고리의 다른 글
| 데이터 캐싱해보기 - Spring Cache와 Caffeine (0) | 2023.08.14 |
|---|---|
| 예제로 QueryDSL 사용해보기 (0) | 2023.07.19 |
| 느린 응답 26배 빠르게 개선해보기 (2) | 2023.07.16 |
| 테스트를 알아보자 With 단위, 통합, E2E (0) | 2023.07.06 |
| 동시성 문제와 데드락, 테스트와 해결, 그리고 삽질 (3) | 2023.06.06 |